SRE and Chaos Engineering
Site Reliability Engineering (SRE) is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems.
The main goals are to create scalable and highly reliable software systems.
Chaos Engineering is Injecting the chaos into our complex system and understand how it works.
It is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Gremlin is one of the tool used to conduct this experiment.

Chaos Experiments is all about understanding what happens when the particular service is unavailable ?

Chaos Experiments is not just about conducting the experiments also helps us to understand the system better way.
Why Chaos Engineering ?
- Identify hidden dependencies.
- Helps to identify the dependencies between downstream service, Database, Memcached, reddis or between micro-service.
- Most of the time, we assume a happy scenario’s. Chaos allow us to testing and helping to move towards a production-ready state.
2. Bringing stability.
- Try to discover weaknesses or deviation from the norm
- Embrace the failure. Inject the failure and see how your system/application behaves.
3. Bringing resilience to the app.
- The capacity to recover quickly from difficulties; toughness.
- By testing the possible failure scenario in advance and having a workaround will make app more resilient and able to cope up production outages.
4. It’s a path to reliability of the system.
- It’s a continuous process to move towards reliability by conducting SRE regularly.
What is GameDay?
GameDays were coined by Jesse Robbins when he worked at Amazon and was responsible for availability. Jesse created GameDays with the goal of increasing reliability by purposefully creating major failures on a regular basis.
Typically, a GameDay would run between 2–4 hours, and involve a team of engineers who either develop an application, or support it, but ideally it involved members from both sides of an application.
Goals Of The GameDay?
The goal is to replay as many previous production impacts as possible, to test whether or not the current systems are more or less resilient.
To ensure a new system being put in place has all the right monitoring, alerts and metrics in place before it is deployed to production.
How to Conducts GameDays?
Any chaos experiments broadly have these four steps.
- Prepare Gremlin Gameday workbook.
- Preparedness
- Conducting Gameday.
- Post-mortem.
1.Preparing GameDay Workbook
GameDay Workbook is a template that has all the information about list of experiments we are going to conduct, who is conducting, Roles and Responsibilities, environment we are going to conduct and outcomes of the experiment.
- This will be 2–3 days/week before conducting the experiment.
- The team will have a meeting and discuss the possible list of experiments to conduct.
- Include all groups of people like frontend developer, backend developer, and L1/L2.
- Everyone in the team will come up with a kind of Hypothesis. Like what if Network has 2-sec latency, the app should work as expected.
- List down all the possible experiments and prioritise.
- Decide Roles and Responsibilities and environment we are going to conduct the experiment.
Typical GameDay workbook looks as below.


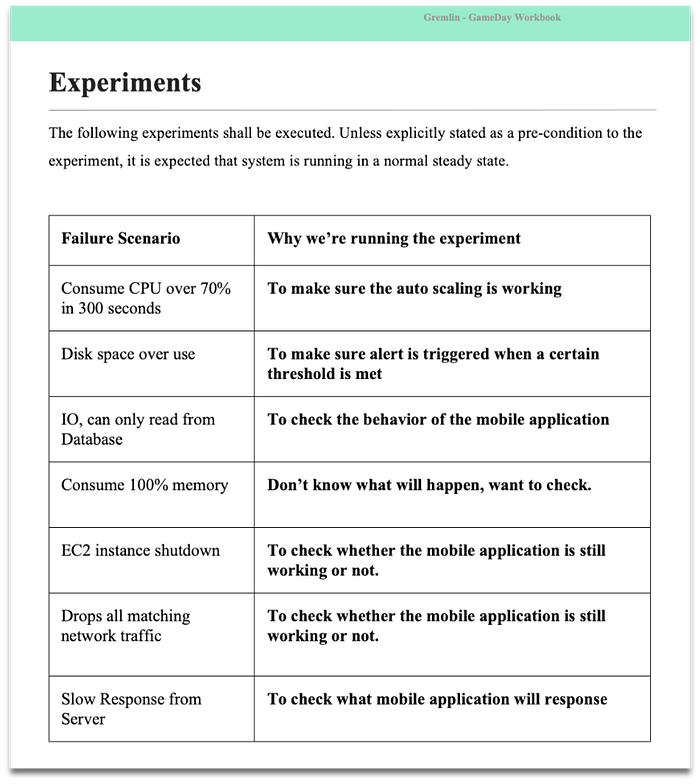
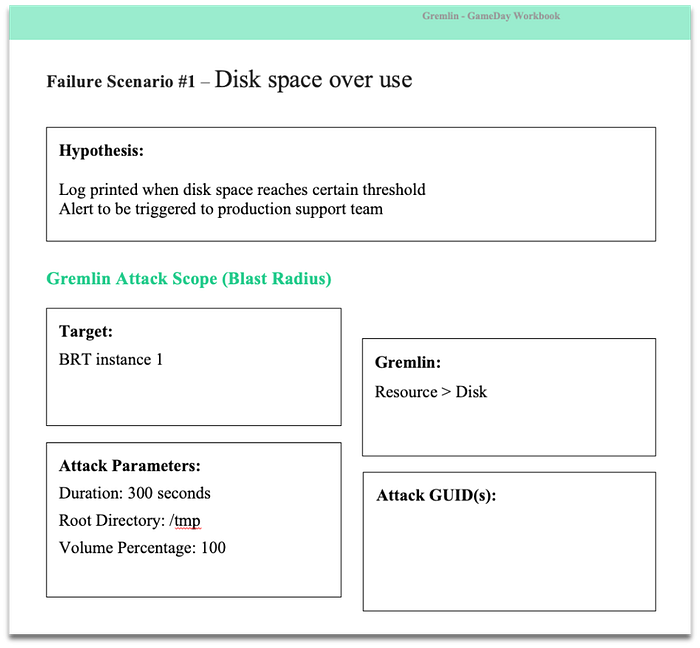

2. Preparedness
- Install the Gremlin agent.
- Gremlin agent will sit on our instance and wait for the Gremlin console’s commands to perform the attack.
- Communicate to the team, L1/L2, dependent system.
3. On GameDay
Team members with individual roles start performing their responsibilities. Following are the roles on GameDay to play.
a. Chaos General
- He will decide when this experiment is completed.
- Can experiment multiple times to get more info and understanding.
- Look after and decide when the abort condition is met.
- Halt condition. If something goes unexpectedly, To halt the experiment immediately.
b. Chaos commander
- Start excepting the experiment using Gremlin console.
c. Chaos Scribe
- Will record the experiment result based on the monitoring and alerting system.
- Record the observation made on the system.
d. Chaos Observer
- Gather all the data and co-relate effects of testing.
- Will test the app and check how it is impacting.
4. Post-mortem
- This is the place to understand and correlate the result of experiments.
- Create a ticket for the issues.
- Update the Gameday workbook
- Once the issue is fixed, Repeat the experiment and verify the fix.
key Learnings:
- Start small
- Start with a small blast radius.
- Don’t give surprises by bringdown the whole system.
2. Don’t stop
- Make it habitual and keep running the experiments.
3. System steady
- Helps your system, ready for the real turbulent conditions in productions
4. Run Experiments
- Run experiments to improve our system and for more understanding.
References
- SRE — How google runs production systems.
- Gremlin — Step-by-Step guide Chaos Engineering
- Video’s — Chaos conf 2020
Happy chaos Engineering.. Happy learning !!